Mert Kilickaya
Hello! I am an AI researcher. My goal is to help automate knowledge discovery, and then turn the discovered knowledge into useful products.
I currently focus on biomarker discovery. Previously, I worked on continual pre-training agents at Learning to Learn Lab, and I completed my PhD in deep learning at the Qualcomm Labs under Arnold Smeulders.
Beyond research, I enjoy creating visual memories whenever I can.
News
Experience

Agendia, Amsterdam, Netherlands
ML Researcher (Biomarker Discovery)

Learning to Learn Lab, Eindhoven University of Technology, Netherlands
ML Researcher (Continual Pretraining Agents)

Qualcomm Labs, University of Amsterdam, Netherlands
PhD Researcher (Deep Learning for Vision)

Huawei Visual Search Lab, Helsinki, Finland
Research Intern (Multimodal Learning)
Research
A selected list of papers and projects.
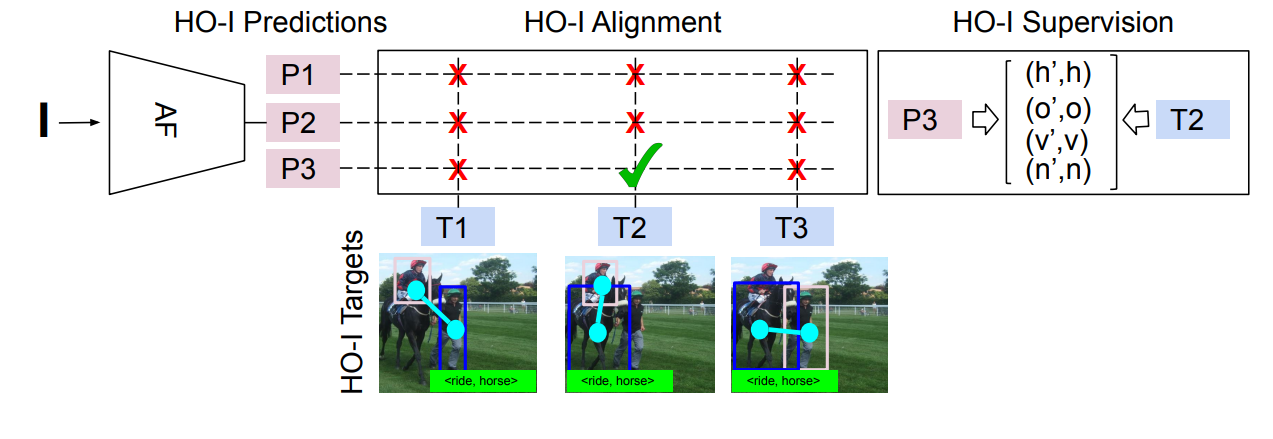
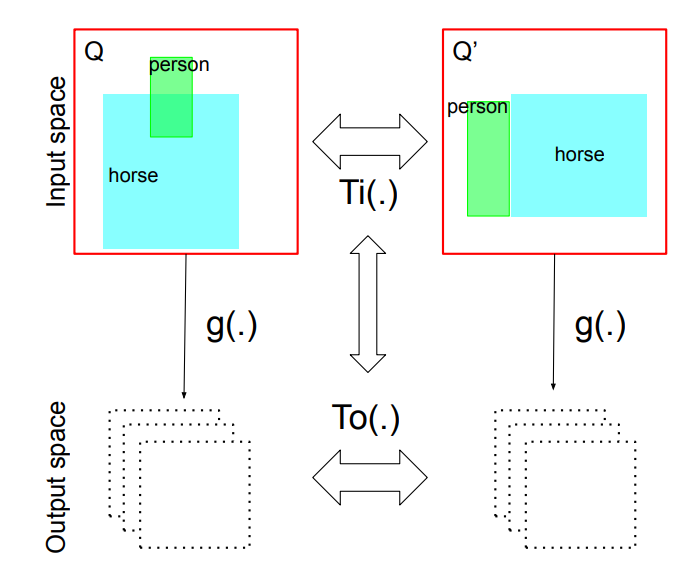

Patents
Visual Image Search via Conversational Interaction (Huawei)
Mert Kilickaya, Baiqiang XIA
Network for Interacted Object Localization (Qualcomm)
Mert Kilickaya, Arnold Smeulders
Subject-Object Interaction Recognition Model (Qualcomm)
Mert Kilickaya, Stratis Gavves, Arnold Smeulders
Context-driven Learning of Human-object Interactions (Qualcomm)
Mert Kilickaya, Noureldien Hussein, Stratis Gavves, Arnold Smeulders
Supervision
I am very fortunate to have crossed paths with these talented individuals.


Fangqin Zhou (PhD, TU/e)


Tommie Kerssies (MSc, TU/e)


